第 5 章 内存系统
内存系统
内存系统特征概览
- 预定义内存映射
- 位带操作
- 非对齐访问
- 支持大小端配置
内存映射
预定义内存的好处:
- 方便 CM3 单片机的移植;
- 允许厂商灵活分配地址存储空间。
存储空间的一些位置用于调试组件等私有外设,这个地址段被称为“私有外设区”。私有外设区的组件包括 :
- 闪存地址重载及断点单元(FPB)
- 数据观察点单元(DWT)
- 仪器化跟踪宏单元(ITM)
- 嵌入式跟踪红单元(ETM)
- 跟踪端口接口单元(TPIU)
- ROM 表
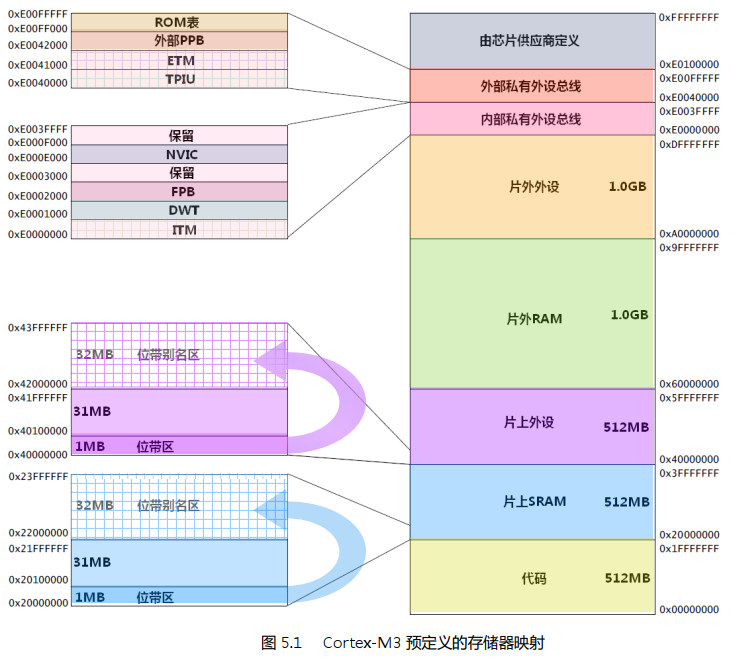
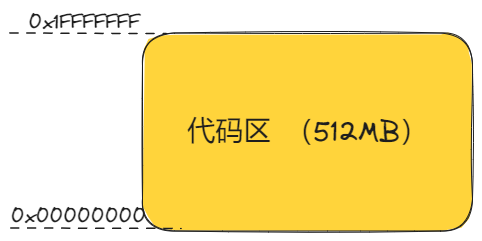
代码区
CM3 的地址空间是 4GB, 程序可以在代码区,内部 SRAM 区以及外部 RAM 区中执行。但是因为指令总线与数据总线是分开的,最理想的是把程序放到代码区,从而使取指和数据访问各自使用自己的总线,并行不悖 。
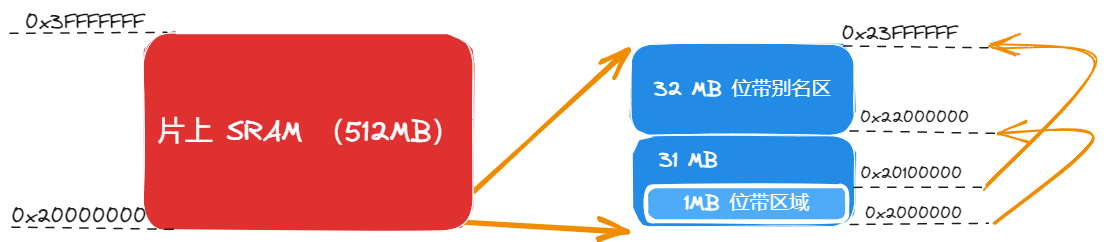
片上 SRAM
内部 SRAM 区的大小是 512MB,用于让芯片制造商连接片上的 SRAM,这个区通过系统总线来访问。
在这个区的下部,有一个 1MB 的区间,被称为“位带区”。该位带区还有一个对应的、 32MB 的“位带别名(alias)区”。位带区对应的是最低的 1MB 地址范围[0x20000000:0x20100000],而位带别名区里面的每个字(一个字 32 位,4 字节)对应位带区的一个比特。访问位带区需要通过访问位带别名区进行访问,。位带操作只适用于数据访问,不适用于取指。
通过位带的功能,可以把多个布尔型数据打包在单一的字中,却依然可以从位带别名区中,像访问普通内存一样地使用它们。
位带别名区中的访问操作是原子的,消灭了传统的“读-改-写”三步曲。
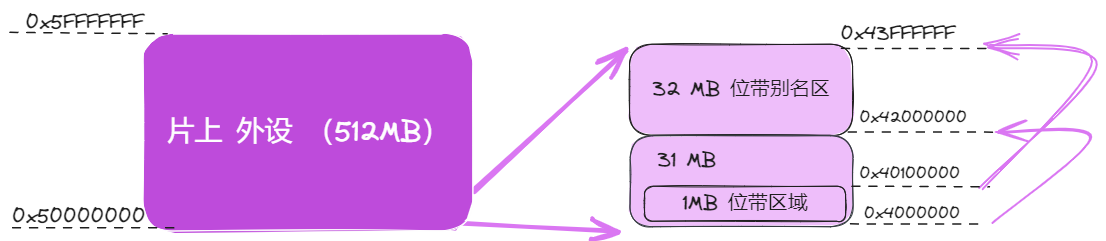
片上外设
这个区中也有一条 32MB 的位带别名,以便于快捷地访问外设寄存器,用法与内部 SRAM 区中的位带相同。例如,可以方便地访问各种控制位和状态位。要注意的是,外设区内不允许执行指令。
片外 RAM 和 片外 RAM
两个 1GB 的范围,分别用于连接外部 RAM 和外部设备,它们之中没有位带。两者的区别在于外部 RAM 区允许执行指令,而外部设备区则不允许。
最后 0.5GB 的隐秘地带
包括了
系统级组件
内部私有外设总线
- 嵌套向量中断控制器(NVIC)
- 闪存地址重载及断点单元(FPB)
- 仪器化跟踪宏单元(ITM)
- 数据观察点单元(DWT)
外部私有外设总线
- 嵌入式跟踪红单元(ETM)
- 跟踪端口接口单元(TPIU)
MCU 厂商定义的系统外设
私有外设总线有两条:
- AHB 私有外设总线,只用于 CM3 内部的 AHB 外设,它们是: NVIC, FPB, DWT 和 ITM;
- APB 私有外设总线,既用于 CM3 内部的 APB 设备,也用于外部设备(这里的“外部”是对内核而言)。
CM3 允许器件制造商再添加一些片上 APB 外设到 APB 私有总线上,它们通过 APB 接口来访问。
CM3 中的 MPU 是选配的,由芯片制造商决定是否配上。
内存访问属性
内存的 4 种访问属性:
- 缓冲
- 缓存
- 执行
- 共享
如果配了 MPU,则可以通过它配置不同的存储区,并且覆盖缺省的访问属性。 CM3 片内没有配备缓存,也没有缓存控制器,但是允许在外部添加缓存。
地址空间可以通过另一种方式分为 8 个 512MB 等份:
- 代码区(
0x00000000-0x1FFFFFFF);- 可执行;
- 缓存属性为不可缓存;
- 此区亦允许布设数据存储器。在此区上的数据操作是通过数据总线接口的(估计读数据使用D-Code,写数据使用 System),且在此区上的写操作是缓冲的。
- SRAM 区(
0x20000000–0x3FFFFFFF);- 可执行;
- 写操作是缓冲的,并且可以选择 WB-WA(Write Back, Write Allocated) 缓存属性。
- 片上外设区(
0x40000000–0x5FFFFFFF) ;- 不可执行;
- 不可缓存。
- 外部 RAM 区的前半段(
0x60000000-0x7FFFFFFF),该区可用于布设片上 RAM 或片外 RAM ;- 可执行;
- 可缓存(缓存属性为 WB-WA) 。
- 外部 RAM 区的后半段(
0x80000000–0x9FFFFFFF);- 可执行;
- 不可缓存;
- 外部外设区的前半段(
0xA0000000–0xBFFFFFFF) ;- 不可执行;
- 不可缓冲,需要严格按顺序操作(用于片外外设的寄存器,也用于多核系统中的共享内存。);
- 外部外设区的后半段(
0xC0000000–0xDFFFFFFF) ,目前与前半段的功能完全一致 ; - 系统区(
0xE0000000–0xFFFFFFFF) ;- 此区是私有外设和供应商指定功能区。此区不可执行代码;
- 系统区涉及到很多关键部位,因此访问都是严格序列化的(不可缓存,不可缓冲) ;
- 供应商指定功能区则是可以缓存和缓冲的。
默认内存访问权限
CM3 有一个缺省的存储访问许可,它能防止使用户代码访问系统控制存储空间,保护 NVIC、 MPU 等关键部件。缺省访问许可在下列条件时生效:
没有配备 MPU
配备了 MPU,但是 MPU 被使能

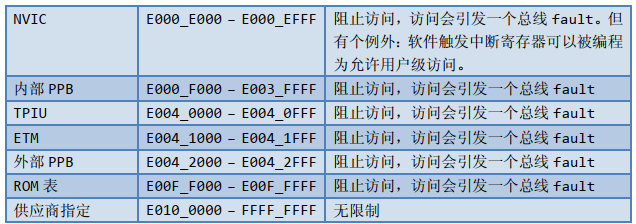
位带操作
支持了位带操作后,可以使用普通的加载/存储指令来对单一的比特进行读写。在 CM3 中,有两个区中实现了位带。其中一个是 SRAM 区的最低 1MB 范围,第二个则是片内外设区的最低 1MB 范围。
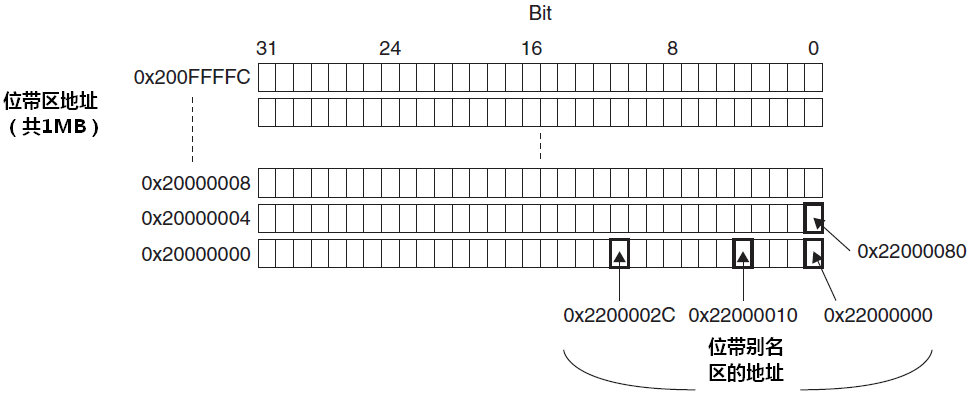
举例:欲设置地址 0x2000000 中的比特 2,则使用位带操作的设置过程如下图所示:
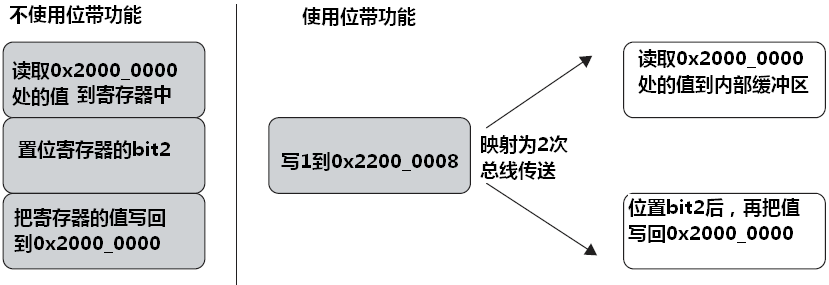



尽管 Cortex-M3 没有用于操作比特的特殊指令,访问被定义为 bit-band 的内存区域会被自动转换为 bit-band 操作。
CM3 使用如下术语来表示位带存储的相关地址
位带区: 支持位带操作的地址区
位带别名: 对别名地址的访问最终会变换成对位带区的访问(注意:这中途有一个地址映射过程)
在位带区中,每个比特都映射到别名地址区的一个字——这是个只有 LSB 才有效的字。当一个别名地址被访问时,会先把该地址变换成位带地址。
- 对于读操作,读取位带地址中的一个字,再把需要的位右移到 LSB,并把 LSB 返回。
- 对于写操作,把需要写的位左移至对应的位序号处,然后执行一个原子的“读-改-写”过程。
支持位带操作的两个内存区的范围是:
0x20000000-0x200FFFFF(SRAM 区中的最低 1MB)对于 SRAM 位带区的某个比特,记它所在字节地址为 A,位序号为 n(0<=n<=7),则该比特在别名区的地址为:
0x40000000-0x400FFFFF(片上外设区中的最低 1MB)对于片上外设位带区的某个比特,记它所在字节的地址为 A,位序号为 n(0<=n<=7),则该比特在别名区的地址为:
上式中,“4”表示一个字为 4 个字节,“8”表示一个字节中有 8 个比特。
这里再不嫌啰嗦地举一个例子:
在地址
0x20000000处写入0x3355AACC读取地址
0x22000008。本次读访问将读取0x20000000,并提取比特 2,值为 1。往地址
0x22000008处写 0。本次操作将被映射成对地址0x20000000的“读-改-写”操作(原子的),把比特 2 清 0。现在再读取 0x20000000,将返回 0x3355AAC8(bit[2] 已清零)。
位带别名区的字只有 LSB 有意义。另外,在访问位带别名区时,不管使用哪一种长度的数据传送指令(字/半字/字节),都把地址对齐到字的边界上,否则会产生不可预料的结果。
位带操作的优越性
位带操作有什么优越性呢?最容易想到的就是通过 GPIO 的管脚来单独控制每盏 LED 的点亮与熄灭。另一方面,也对操作串行接口器件提供了很大的方便 。
位带操作还能用来化简跳转的判断。当跳转依据是某个位时,以前必须这样做:
- 读取整个寄存器
- 掩蔽不需要的位
- 比较并跳转
现在只需:
- 从位带别名区读取状态位
- 比较并跳转
使代码更简洁,这只是位带操作优越性的初等体现。位带操作还有一个重要的好处是在多任务中,用于实现共享资源在任务间的“互锁”访问。多任务的共享资源必须满足一次只有一个任务访问它——亦即所谓的“原子操作”。以前的读-改-写需要 3 条指令,导致这中间留有两个能被中断的空当。通过使用 CM3 的位带操作,就可以消灭上例中的紊乱危象。 CM3 把这个“读-改-写”做成一个硬件级别支持的原子操作,不能被中断。
其它数据长度上的位带操作
位带操作并不只限于以字为单位的传送。亦可以按半字和字节为单位传送。例如,可以使用LDRB/STRB 来以字节为长度单位去访问位带别名区,同理可用于 LDRH/STRH。但是不管用哪一个对子,都必须保证目标地址对齐到字的边界上。
在 C 语言中使用位带操作
不幸的是,在 C 编译器中并没有直接支持位带操作。比如, C 编译器并不知道同一块内存能够使用不同的地址来访问,也不知道对位带别名区的访问只对 LSB 有效。欲在 C 中使用位带操作,最简单的做法就是#define 一个位带别名区的地址。 例如:
#define DEVICE_REG0 ((volatile unsigned long *) (0x40000000))
#define DEVICE_REG0_BIT0 ((volatile unsigned long *) (0x42000000))
#define DEVICE_REG0_BIT1 ((volatile unsigned long *) (0x42000004))
*DEVICE_REG0 = 0xAB; // 使用正常地址访问寄存器
*DEVICE_REG0 = *DEVICE_REG0 | 0x2; // 使用传统方法设置 bit1
*DEVICE_REG0_BIT1 = 0x1; // 通过位带别名地址设置 bit1
为简化位带操作,也可以定义一些宏。比如,我们可以建立一个把“位带地址+位序号”转换成别名地址的宏,再建立一个把别名地址转换成指针类型的宏:
//把“位带地址+位序号”转换成别名地址的宏
#define BITBAND(addr, bitnum) ((addr & 0xF0000000)+0x2000000+((addr &
0xFFFFF)<<5)+(bitnum<<2))
//把该地址转换成一个指针
#define MEM_ADDR(addr) *((volatile unsigned long *) (adr))
MEM_ADDR(DEVICE_REG0) = 0xAB; // 使用正常地址访问寄存器
MEM_ADDR(DEVICE_REG0)= MEM_ADDR(DEVICE_REG0) | 0x2; // 传统做法
MEM_ADDR(BITBAND(DEVICE_REG0,1)) = 0x1; // 使用位带别名地址
请注意:当使用位带功能时,要访问的变量必须用 volatile 来定义。因为 C 编译器并不知道同一个比特可以有两个地址。所以就要通过 volatile,使得编译器每次都如实地把新数值写入存储器,而不再会出于优化的考虑,在中途使用寄存器来操作数据的复本,直到最后才把复本写回— —这会导致按不同的方式访问同一个位会得到不一致的结果。
非对齐数据传输
CM3 支持在单一的访问中使用非(地址)对齐的传送,数据存储器的访问无需对齐。在以前, ARM 处理器只允许对齐的数据传送。这种对齐是说:
- 以字为单位的传送,其地址的最低两位必须是0;
- 以半字为单位的传送,其地址的 LSB 必须是 0;
- 以字节为单位的传送则无所谓对不对齐。
任何一个不能被 4 整除的地址都是非对齐的。而对于半字,任何不能被 2 整除的地址(也就是奇数地址)都是非对齐的。
在 CM3 中,非对齐的数据传送只发生在常规的数据传送指令中,如 LDR/LDRH/LDRSH。其它指令则不支持,包括:
- 多个数据的加载/存储(LDM/STM)
- 堆栈操作 PUSH/POP
- 互斥访问 (LDREX/STREX)。如果非对齐会导致一个用法 fault。
- 位带操作。因为只有 LSB 有效,非对齐的访问会导致不可预料的结果。
事实上,在内部是把非对齐的访问转换成若干个对齐的访问的,这种转换动作由处理器总线单元来完成。这个转换过程对程序员是透明的,因此写程序时不必操心。
但是,因为它通过若干个对齐的访问来实现一个非对齐的访问, 会需要更多的总线周期。为此,可以编程 NVIC,使之监督地址对齐。当发现非对齐访问时触发一个 fault。具体的办法是设置“配置控制寄存器”中的 UNALIGN_TRP 位。这样,在整个调试期间就可以保证非对齐访问能当场被发现。
互斥访问
细心的读者可能会发现, CM3 中没有类似“SWP”的指令。在传统的 ARM 处理器中, SWP 指令是实现互斥体所必需的。到了 CM3,由所谓的互斥访问取代了 SWP 指令,以实现更加老练的共享资源访问保护机制。
在新版的 ARM 处理器中,读/写访问往往使用不同的总线,导致 SWP 无法再保证操作的原子性,因为只有在同一条总线上的读/写能实现一个互锁的传送。
因此,互锁传送必须用另外的机制实现,这就引入了“互斥访问”。互斥访问的理念同 SWP 非常相似,不同点在于:在互斥访问操作下,允许互斥体所在的地址被其它总线 master 访问,也允许被其它运行在本机上的任务访问,但是 CM3能够“驳回”有可能导致竞态条件的互斥写操作。
互 斥 访 问 分 为 加 载 和 存 储 , 相 应 的 指 令 对 子 为 LDREX/STREX, LDREXH/STREXH, LDREXB/STREXB,分别对应于字/半字/字节。为了介绍方便,以 LDREX/STREX 为例讲述它们的使用方式。
LDREX/STREX 的语法格式为:
LDREX Rxf, [Rn, #offset]STREX Rd, Rxf, [Rn, #offset]
LDREX 的语法同 LDR 相同,而 STREX 则不同。 STREX 指令的执行是可以被“驳回”的:
- 当处理器同意执行
STREX时, Rxf 的值被存储到(Rn+offset)处,并且把 Rd 的值更新为 0; - 但若处理器驳回了
STREX的执行,则不会发生存储动作,并且把 Rd 的值更新为 1。
注意
当遇到 STREX 指令时,仅当在它之前执行过 LDREX 指令,且在最近的一条 LDREX 指令执行后,没有执行过其它的 STR/STREX 指令,才允许执行本条 STREX 指令——也就是说只有在 LDREX 执行后,从时间上与之距离最近的一条 STREX 才能成功执行。
这种最严格的规则也是最容易实现的规则。在 CM3 的技术参考手册中,推荐实现者标记出一段有限的地址,只在这段地址中适用互斥访问的规则,而不要对所有 4GB 都限制住。这段地址通常是从 LDREX 指令族给出的地址开始,长度在 16 字节至 4K 字节范围内。但芯片制造商可能更倾向严格的规则。
在使用互斥访问时, LDREX/STREX 必须成对使用。
为什么这种有条件的驳回可以避免紊乱危象呢?让我们举个简单的例子来演示。这个例子由主程序和一个中断服务例程组成。主程序尝试对(R0)自增两次,中断服务例程则把(R0).5
置位。计(R0)的初始值为 0。
MainProgram
;第一次互斥自增
TryInc1st
LDREX r2, [R0]
ADD r2, #1
;执行到这里时,处理器接收到外中断 3 请求,于是转到其中断服务例程 ISREx3 中
STREX R1, R2, [R0] ; STREX 被驳回, R1=1, (R0)=0x20
TryInc2nd
;第二次互斥自增
LDREX r2, [R0]
ADD r2, #1
STREX R1, R2, [R0] ; STREX 得到执行, R1=0, (R0)=0x21
…
ISREx3
;处理器已经自动把 R0-R3, R12, LR, PC, PSR 压入栈
LDR R2, [R0]
ORR R2, #0x20
STR R2, [R0] ;在 ISREx3 中设置了(r0)的 Bit2
BX LR ;返回时,处理器会自动把 R0-R3,R12,LR,PC,PSR 弹出堆栈
上例中,主程序在即将执行第一条 STREX 时,产生了外部中断#3。处理器打断主程序的执行,进入其服务例程 ISREx3,它对(R0)执行了一个写操作(STR),因此在 ISRExt3 返回后, STREX 不再是 LDREX 执行后的第一条存储指令,故而被驳回。从而 ISREx3 对(R0)的改动就不会遭到破坏。随后主程序再次尝试自增运算,这一次在 STREX 执行前没有其它任何形式的存储指令,所有 STREX 成功执行。
如果主程序使用普通的 STR 会怎么样呢?对于第一次自增,主程序的 R2=1,于是执行后(R0)=1,结果,中断服务程序对(R0)的改动在此丢失!
LDREX/STREX 的工作原理其实很简单。仍然以上一段程序为例:当执行了 LDREX 后,处理器会在内部标记出一段地址。原则上,这段地址从 R0 开始,范围由芯片制造商定义。技术手册推荐的范围是在 4 字节至 4KB 之间,但是很多粗线条的实现会标记整个 4GB 的地址。在标记以后, 对于第一个执行到的 STR/STREX 指令,只要其存储的地址落在标记范围内,就会清除此标记(对于整个4GB 地址都被标记的情况,则任何存储指令都会清除此标记)。如果先后执行了两次 LDREX,则以后一个 LDREX 标记的地址为准。
执行 STREX 时,会先检查有没有做出过标记,如果有,还要检查存储地址是否落在标记范围内。只有通过了这两个关卡, STREX 才会执行。否则,就驳回 STREX。
当使用互斥访问时,在 CM3 总线接口上的内部写缓冲会被旁路,即使是 MPU 规定此区是可以缓冲的也不行。这保证了互斥体的更新总能在第一时间内完成,从而保证数据在各个总线主机(master)之间是一致的。 So 系统的设计师如果设计多核系统,则必须保证各核之间看到的数据也是一致的。
端模式
CM3 支持 both 小端模式和大端模式。在绝大多数情况下,基于 CM3 的单片机都使用小端模式— —为了避免不必要的麻烦,在这里推荐读者清一色地使用小端模式。
CM3 中对大端模式的定义还与 ARM7 的不同(小端的定义都是相同的)。在 ARM7 中,大端的方式被称为“字不变大端”,而在 CM3 中,使用的是“字节不变大端”。
请注意:在 AHB 总线上的 BE-8 模式下,数据字节 lane 的传送格式是与小端模式一致的。
在 CM3 中,是在复位时确定使用哪种端模式的,且运行时不得更改。
使用小端的情景:
- 指令预取永远使用小端模式;
- 在配置控制存储空间的访问也永远使用小端模式(包括 NVIC, FPB 等);
- 外部私有总线地址区 0xE0000000 至 0xE00FFFFF 也永远使用小端模式。